Introduction
기존에는 사전 학습된 언어 모델 (language model; LM)을 새로운 downstream task에 적용하기 위해 fine-tuning 방법이 흔히 사용되었다. 하지만, 이를 위해서는 모든 모델 parameter를 업데이트하고 저장해야 하는데, 최근 나온 대규모 언어 모델에 적용하기에는 비용이 너무 많이 든다는 단점이 있다. 예를 들어 2019년 소개된 GPT-2 (774M parameter) 혹은 2020년에 소개된 GPT-3 (175B parameter)에서 각 task에 대해 모델 전체를 fine-tuning하는 것은 매우 어려울 것이다.
참언) 175B parameter는 저장 공간만 하더라도 700GB가 필요하다 (기본 32bit precision 기준).
최근에는 이를 해결하기 위해 좀더 가벼운 lightweight fine-tuning 접근이 제시되고 있다. 이는 모델 전체를 fine-tuning 하는 대신 대부분의 parameter를 그대로 두고 (freeze하고) 모델 일부만 업데이트하거나 작은 모듈을 붙여서 학습하는 방법을 말한다. 대표적인 예로, adapter-tuning은 기존 LM을 구성하는 레이어 사이에 경량의 task-specific (특정 task에 특화된) 레이어를 추가하는 방법이다. 이는 task-specific parameter를 2-4% 수준으로 사용하면서 모델 전체 fine-tuning에 준하는 성능을 낼 수 있었다.
반면, GPT-3와 같이 매우 큰 LM에서는 fine-tuning 없이 자연어로 된 명령을 모델 입력 앞단에 추가하는 것만으로도 task를 수행할 수 있다는 것이 밝혀졌다. 예를 들어, 다음 문장을 요약해라: 를 모델 입력 앞에 추가하면, 모델은 주어진 문장에 대한 요약을 출력하게 된다. 위와 같은 접근 방식을 in-context learning 혹은 prompting이라고 하며, 매우 큰 LM에서 fine-tuning을 대체하는 방법론으로 떠오르고 있다.
본 논문에서는 이러한 prompting에서 영감을 받아 자연어 생성 (natural langauge generation; NLG)을 위해 fine-tuning을 대체할 수 있는 가벼운 기법으로 prefix-tuning을 제시한다. 이는 간단히 설명하면, prompting처럼 다음 문장을 요약해라: 와 같이 사람이 정한 접두어 (prefix)를 사용하지 않고, 역전파를 통해 최적화된 벡터 형태의 prefix를 사용하는 방법이다. 이는 사람이 직접 접두어를 생각해내기 힘든 task에도 적용할 수 있을 뿐만 아니라, 연속적인 벡터를 최적화하기 때문에 기존의 이산 (discrete) 형태의 접두어보다 표현력이 높다는 장점이 있다.
참언) 다음 문장을 요약해라: 와 같은 자연어 접두어를 모델에 입력하게 되면, 토큰화를 거친 후에 각 토큰은 사전에 학습된 토큰 임베딩 (token embedding) 벡터로 매핑된다. 즉, 이미 학습된 이산화된 토큰 임베딩 내에서 벡터를 골라서 모델 입력 앞단에 추가한다고 할 수 있다. 반면, prefix tuning에서는 입력에 들어가는 접두어를 연속적인 벡터 상태 그대로 최적화하기 때문에, 기존의 토큰 임베딩 외의 벡터값을 띨 수 있다. 간단한 예로, 여러 토큰의 의미를 하나의 벡터에 담기 위해 각 토큰 벡터의 중간값을 띨 수 있다.
다음은 fine-tuning과 prefix tuning의 차이를 도식적으로 나타낸다.
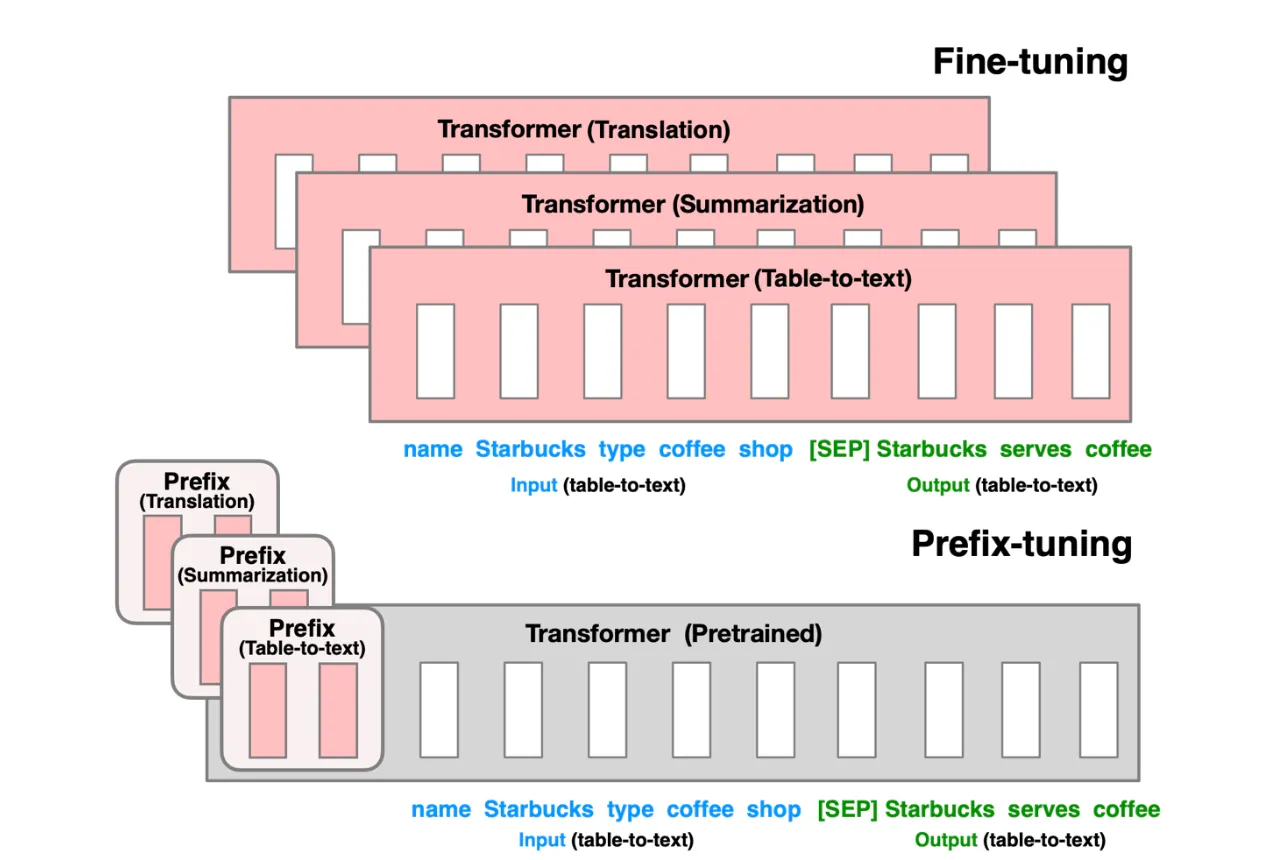
Prefix-tuning은 기존의 fine-tuning (혹은 lightweight fine-tuning) 기법과 비교하여 다음과 같은 장점을 가진다.
- 하나의 모델과 매우 작은 규모의 task-specific parameter를 필요로 한다 (~250K 규모)
- 하나의 배치 내에서 입력마다 다른 prefix를 사용하여 여러 개의 task를 동시에 처리할 수 있다.
Method (상세)
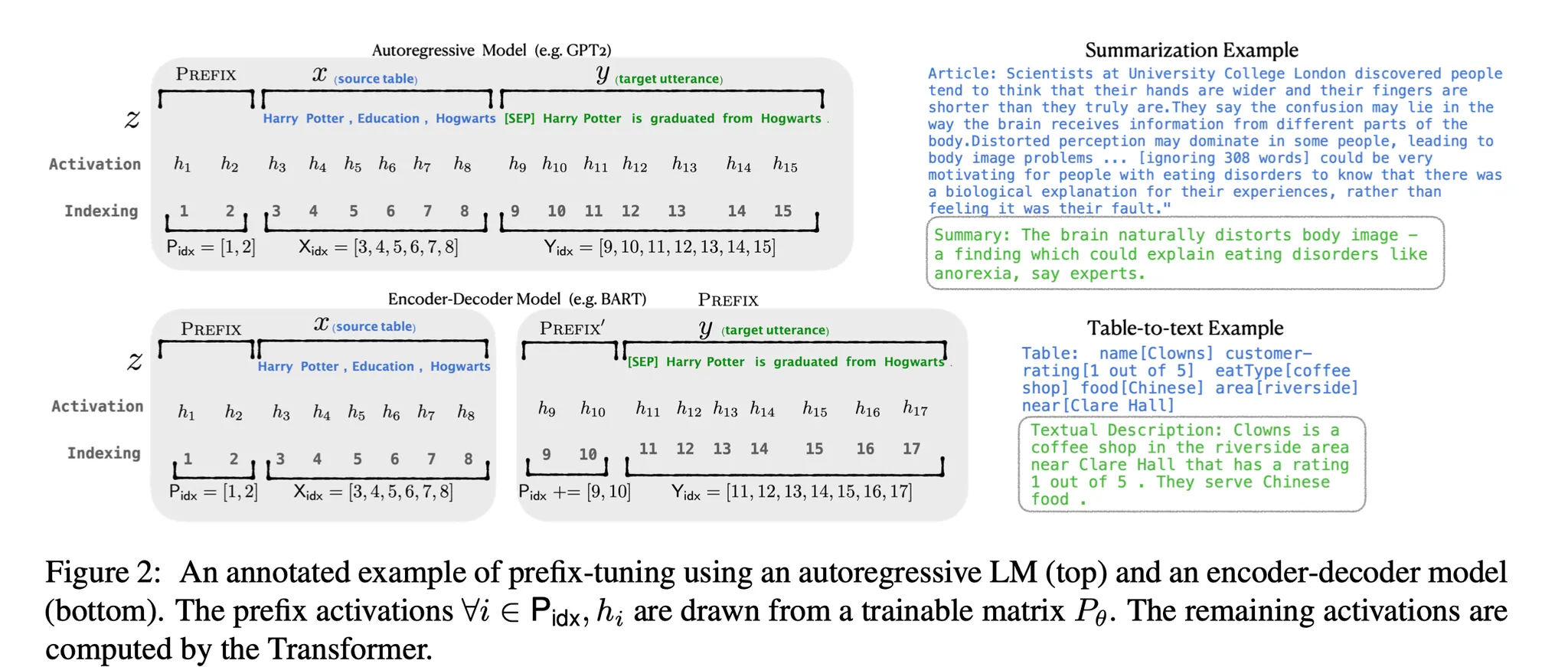
위와 그림과 같이 모델 앞단 activation ($h_1$, $h_2$)을 prefix로 대체하며, 그 값은 학습 가능한 행렬 $P_\theta$로 표현한다. Prefix의 길이는 달라질 수 있으며, prefix에 해당하는 인덱스 리스트를 $P_{idx}$로 표현한다. Prefix 이후 activation ($h_3$, $h_4$, …)은 attention 기법에 의거 prefix의 영향을 받게 된다. 즉, prefix tuning의 핵심은 모델로 하여금 목표로 하는 task에 맞게 activation ($h_3$, $h_4$, …)을 출력하도록 모델을 잘 조종하는 prefix를 학습하는 것이다 (이는 딥러닝에서 일반적으로 사용하는 역전파를 통해 이루어진다).
Main Results
Experimental Setup
본 논문에서는 prefix-tuning의 성능을 실험적으로 보이기 위해 다음과 같은 실험 세팅을 사용한다.
- Task
- Table-to-text
- Summarization
- 모델
- Table-to-text: GPT-2 Medium (355M), GPT-2 Large (774M)
- Summarization: BART Large (400M)
- 기존 방법론
- Fine-tune: 전체 모델 fine-tuning
- FT-top2: 모델의 최상단 레이어 2개만 fine-tuning
- Adapter: 모델 중간에 task-specific 레이어를 추가하는 lightweight fine-tuning 기법
- 에폭=10, batch size=5, learning rate=5e-5, prefix length=10
- 에폭당 학습 시간: 0.2-1.25 시간 (TITAN X, V100)
Table-to-text Generation
다음과 같이 3가지 table-to-text generation 데이터셋 전반에 걸쳐 prefix tuning은 전체 parameter의 0.1% 규모의 task-specific parameter를 사용하면서 기존 lightweight fine-tuning 기법 성능을 뛰어넘고, 모델 전체를 업데이트하는 fine-tune에 준하는 성능을 내는 것을 확인할 수 있다.

Summarization
다음과 같이 XSUM 데이터셋에 대한 텍스트 요약 성능을 확인한 결과, 모델 전체를 업데이트하는 fine-tune에서 성능이 크게 떨어지지 않는 것을 확인할 수 있다.
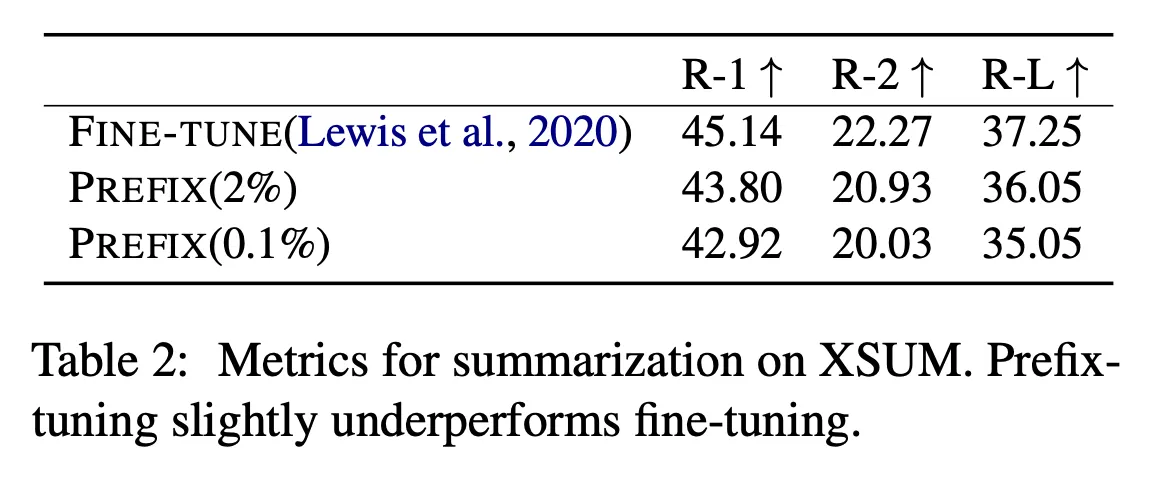
Low-data Setting
다음과 같이 학습에 사용할 수 있는 데이터가 적은 상황 (0~500개 샘플)에서는 더 가벼운 prefix tuning이 fine-tuning보다 전반적으로 높은 성능을 내는 것을 확인할 수 있다. 아래 오른쪽 상단은 요약 성능, 오른쪽 하단은 table-to-text 성능을 나타낸다. 왼편에는 table-to-text 실제 출력 예시를 확인할 수 있는데, prefix tuning 쪽의 출력이 주어진 정보를 더 많이 반영하고, 더 정확하게 반영하는 것을 볼 수 있다.
Extrapolation
아래는 학습에 사용되지 않은 데이터에 대한 평가 성능을 확인하기 위한 결과를 나타낸다. 뉴스 요약에 대한 학습을 거친 후 스포츠 요약을 평가햇을 때, prefix tuning의 성능이 더 높은 것을 확인할 수 있다. 추가로, 뉴스 주제에 한정지어서 요약 성능을 평가하면 prefix tuning의 성능이 높은 것을 확인할 수 있다.

Ablation Results (일부)
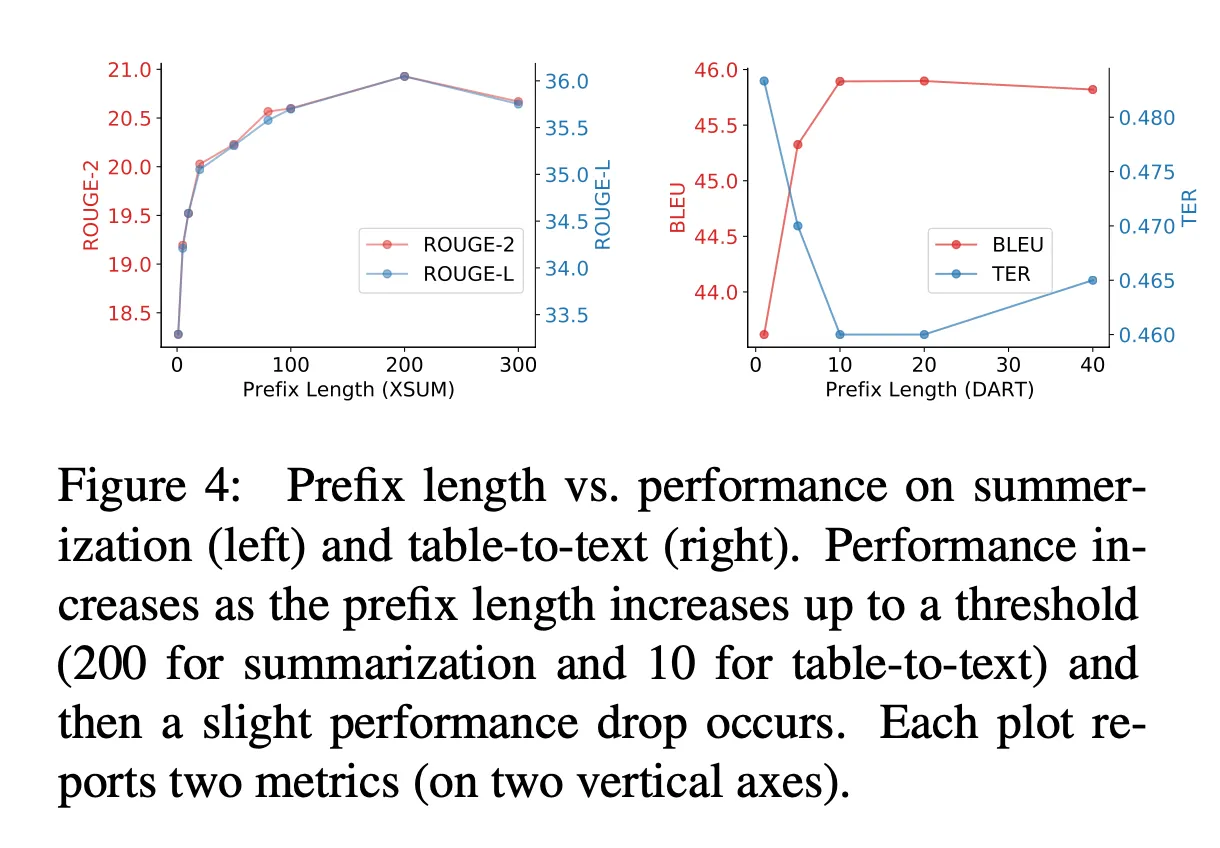
Prefix Length
아래는 prefix length를 달리 했을 때 요약 및 table-to-text 성능의 변화를 나타낸다. Prefix length가 높을수록 학습 가능한 parameter의 개수가 늘어남에도 불구하고 prefix length가 꼭 길다고 성능이 높아지는 것은 아니다. 요약에서는 prefix length가 200, table-to-text는 10일때 성능이 최고치를 찍고, 이후에는 성능이 줄어드는 것을 확인할 수 있다.
Conclusion
본 논문에서는 NLG task에 사용하기 위해 fine-tuning을 대체하는 경량 기법인 prefix tuning을 제시한다. 학습 가능한 prefix를 모델 입력에 추가하는 방식의 prefix tuning을 통해, fine-tuning에 비해 1000배 적은 task-specific parameter를 사용하면서 비슷한 성능을 유지하면서, 데이터가 적거나 학습 데이터에서 벗어나는 상황에 대해 오히려 높은 성능을 낼 수 있다는 것을 확인했다.
'AI > 논문 리뷰' 카테고리의 다른 글
| [논문리뷰] GLaM: Efficient Scaling of Language Models with Mixture of Experts (2) | 2023.10.09 |
|---|