Token Bucket
토큰 버켓의 경우 사전에 정해진 용량을 갖는다. 토큰은 주기적으로 사전에 설정된 비율로 버켓에 저장된다. 그리고 버켓이 꽉차게 되면 정해진 용량을 초과하여 토큰을 추가하지 않는다.
각 API 요청은 1개의 토큰을 사용한다. 요청이 오면 버켓에 적어도 1개의 토큰이 존재하는지 확인한다. 존재하는 경우 1개의 토큰을 버켓에서 꺼내고 요청이 처리된다. 버켓이 비어있는 경우 요청들은 버려진다.
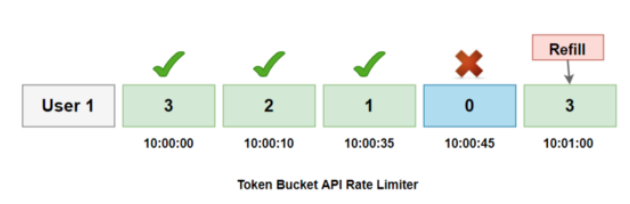
- 위 사진을 보면 유저마다 분당 3개의 요청량 제한이 설정되어있다.
- 1번 유저가 10:00:00에 첫 번째 요청을 보냈을 때 토큰은 3개가 존재하므로 해당 요청은 정상 처리되며 잔여 토큰은 2개로 감소한다.
- 10:00:10에 유저의 두 번째 요청이 오고 토큰은 2개가 존재하기 때문에 정상 처리되며 잔여 토큰은 1개로 감소한다.
- 세 번째 요청이 10:00:35에 오고 토큰은 1개가 존재하기 때문에 정상 처리되며 잔여 토큰은 0개로 감소한다.
- 네 번째 요청이 10:00:45에 왔지만 잔여 토큰이 없기 때문에 해당 요청은 거부된다.
- 10:01:00이 되면 잔여 토큰이 초기화되어 총 3개의 토큰이 버켓에 존재하게 된다.
버켓 요소
각 버켓은 다음과 같은 요소를 가지고 있다.
- key: 버켓을 나타내는 고유한 값
- maxAmount: 버켓이 가지고 있을 수 있는 최대 토큰의 개수
- refillTime: 리필 주기
- refillAmount: 리필 시 버켓에 추가될 토큰의 개수
- value: 버켓에 있는 토큰의 개수
- lastUpdate: 버켓이 마지막으로 업데이트된 시간
In-Memory Cache 사용
위 알고리즘이 올바르게 동작하려면 아래의 정보들이 필요하다.
- 유저 ID 또는 클라이언트 ID 등 API 요청을 식별할 수 있는 정보
- 버켓 잔여 토큰 수
- 요청의 타임스탬프
명심할점은, 우리가 외부에서 발생하는 트래픽의 속도를 통제할 수 없기 때문에 언제든 트래픽이 급증하는 것을 대비해야 한다는 것이다. 데이터베이스를 사용하는 것은 디스크 접근 속도가 느리기 때문에 좋은 선택지가 아니다. 대신 인메모리 캐시가 괜찮은 선택지가 될 것이다. 인메모리 캐시는 굉장히 빠르고 TTL같은 기술을 지원해주기 때문이다. 예를 들어 레디스의 경우 INCR, EXPIRE와 같은 유용한 명령어를 제공해준다.

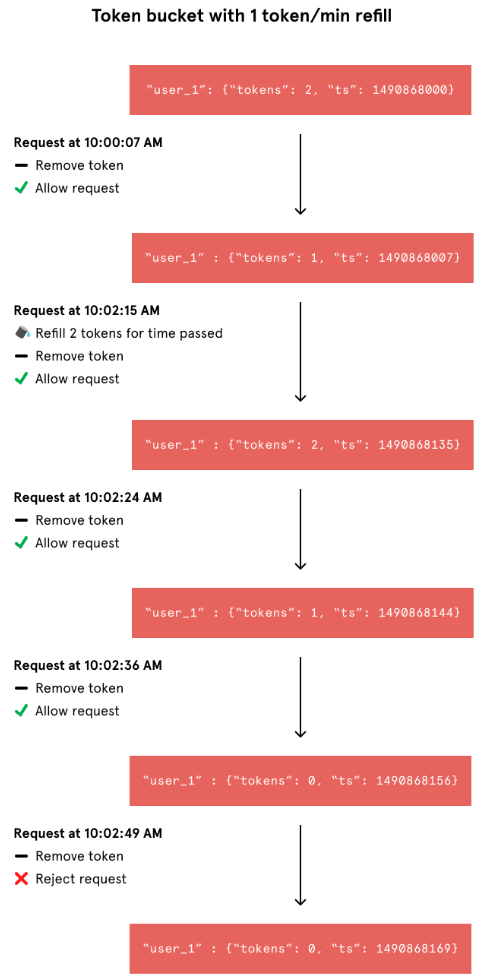
각 유저별로 마지막 요청의 타임스탬프와 잔여 토큰 수를 해시 자료구조로 저장한다. user_1은 버켓에 2개의 잔여 토큰이 있으며 Thursday, March 30, 2017 at 10:00 GMT에 마지막 요청을 보냈다.
유저에게 새로운 요청이 올 때 마다 Rate limiter는 사용량을 추적하기 위해 여러 작업을 수행해야한다. 레디스에서 정보를 가져오고 정해둔 리필 속도와 사용자의 마지막 요청 시간을 기반으로 토큰을 리필해야한다. 그리고 현재 요청의 타임스탬프와 새로운 잔여 토큰 정보로 업데이트 해야한다.
Distributed Rate Limiting, Race Condition and Concurrency
토큰 버켓 알고리즘이 간단하고 적은 메모리를 사용하지만 문제는 레디스에 입력해야하는 명령어들이 원자적이지 않다는 것이다. 분산 환경에서 "읽고 다시 쓰는" 행동은 레이스 컨디션을 유발하고 이로 인해 Rate limiter가 정상적으로 동작하지 않을 수 있다.
따라서 원자성을 보장하기 위해 레디스에 명령어를 입력할 때 락을 사용할수도 있다. 그러나 이는 동일한 유저의 요청 속도를 느려지게하고 복잡성을 유발한다. 대신 Lua 스크립트를 사용하는것이 하나의 대안이 될 수 있다.
장점
- 토큰 버켓 알고리즘은 매우 간단하기 때문에 구현이 쉽다.
- 메모리를 적게 사용한다.
- 스파이크성으로 들어오는 트래픽을 대응할 수 있다. 버켓에 토큰이 남아있는 한 모든 요청을 수용할 수 있다. 스파이크성 트래픽은 흔하지 않기에 이는 굉장히 중요한 부분이다.
단점
- 위에서 이야기했듯이 분산 환경에서 동일 유저가 동시에 요청을 보내면 레이스 컨디션이 발생할 수 있다.
Stripe, Amazon Elastic Compute Cloud 또는 AWS EC2에서 토큰 버켓 알고리즘을 사용한다.
Leaky Bucket
토큰 버켓과 유사하게 Leaky 버켓에도 각 클라이언트 별로 사전에 정해진 용량이 존재한다. 그러나 토큰 버켓 알고리즘과는 다르게 Leaky 버켓은 클라이언트의 요청에 의해 버켓에 토큰이 채워진다. 그리고 요청은 버켓에서 일정한 속도로 꺼내어 처리된다. 요청이 도착하는 속도가 처리되는 속도보다 빠르면 버켓에 공간이 생길 때 까지 추가 요청은 버려진다.
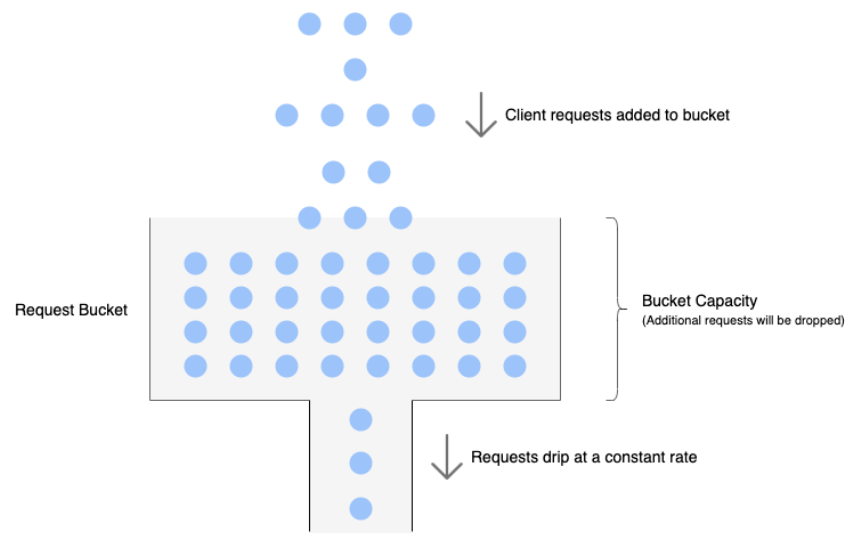
보다시피 Leaky 버켓 알고리즘은 요청이 거의 일정한 속도로 처리되어 스파이크로 들어오는 요청들을 완화시킨다. 요청이 스파이크로 들어온다 하더라도 나가는 응답은 항상 동일한 속도로 유지된다. 이 알고리즘에서는 제한된 크기를 가진 큐를 사용하고 FIFO 방식으로 큐에서 일정한 속도로 요청을 처리한다.
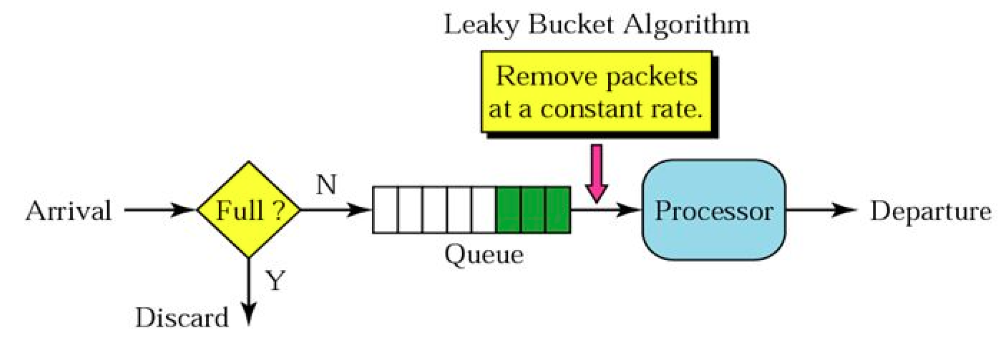
유저의 요청이 들어오면,
- 큐가 꽉 찼는지 검사한다.
- 큐가 꽉 찼다면 추가 요청은 버려진다.
- 큐가 꽉 찬게 아니라면 요청을 큐에 넣고 순차적으로 처리한다.
Leaky 버켓 알고리즘의 버켓 크기는 큐의 크기와 동일하다. 그리고 큐는 고정된 속도로 요청을 처리한다.
장점
- 제한된 큐 크기를 고려하면 효율적인 메모리를 사용한다.
- 요청이 고정된 속도로 처리되기 때문에 안정적인 속도가 필요한 유즈케이스에 적합하다.
단점
- 트래픽이 폭주하는 경우 큐에 이전 요청들이 채워지기 때문에 해당 요청들이 제시간에 처리되지 않으면 새로운 요청들이 버려진다.
Shopify가 Leaky 버켓 알고리즘을 사용한다.
Fixed Window
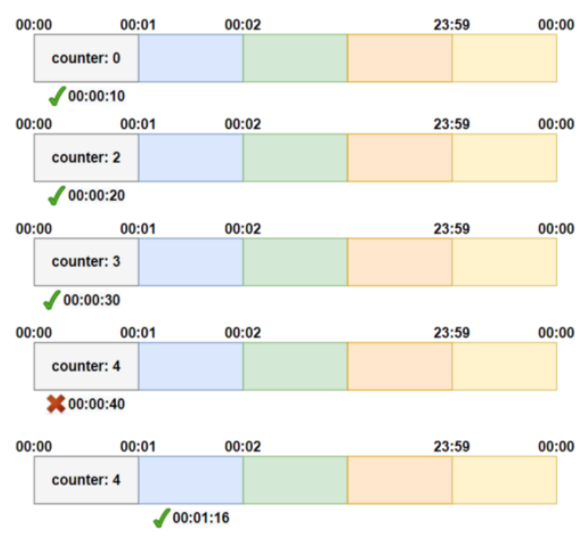
고정 윈도우 알고리즘은 가장 기본적은 Rate limit 알고리즘 중 하나이며 아마 가장 간단하게 구현할 수 있는 방법일 것이다. 정해진 윈도우마다 카운터를 가지고 매 요청마다 카운터를 증가시킨다. 최대 요청 크기에 도달하면 다음 윈도우가 오기전까지 추가 요청은 모두 버려진다.
구현
토큰 버켓 알고리즘과는 다르게 이 방법의 레디스 명령은 원자적이다. 각 요청은 요청의 타임스탬프가 포함된 키값을 증가시킨다.

user_1은 2017년 3월 30일 10:00:00 ~ 10:00:59 사이에 1개의 요청을 보냈다. 위 레디스 키에는 2017년 3월 30일 10:00:00부터 2017년 3월 30일 10:00:59 타임스탬프 사이의 모든 항목이 포함된다. 예를 들어 2017년 3월 30일 10:00:10와 2017년 3월 30일 10:00:20에 발생한 모든 요청의 레디스 키는 2017년 3월 30일 10:00:00 타임스탬프에 포함된다. 이것이 레디스 명령을 원자적으로 만드는 이유이다.
주어진 타임스탬프에 대한 요청 수를 증가시킬 때 해당 값을 Rate limit 크기와 비교하여 요청을 받을 지 거부할 지 결정한다. 또한 카운터가 영원히 남아있지 않도록 하기 위해 현재 분이 지나면 키가 만료되도록 설정한다.
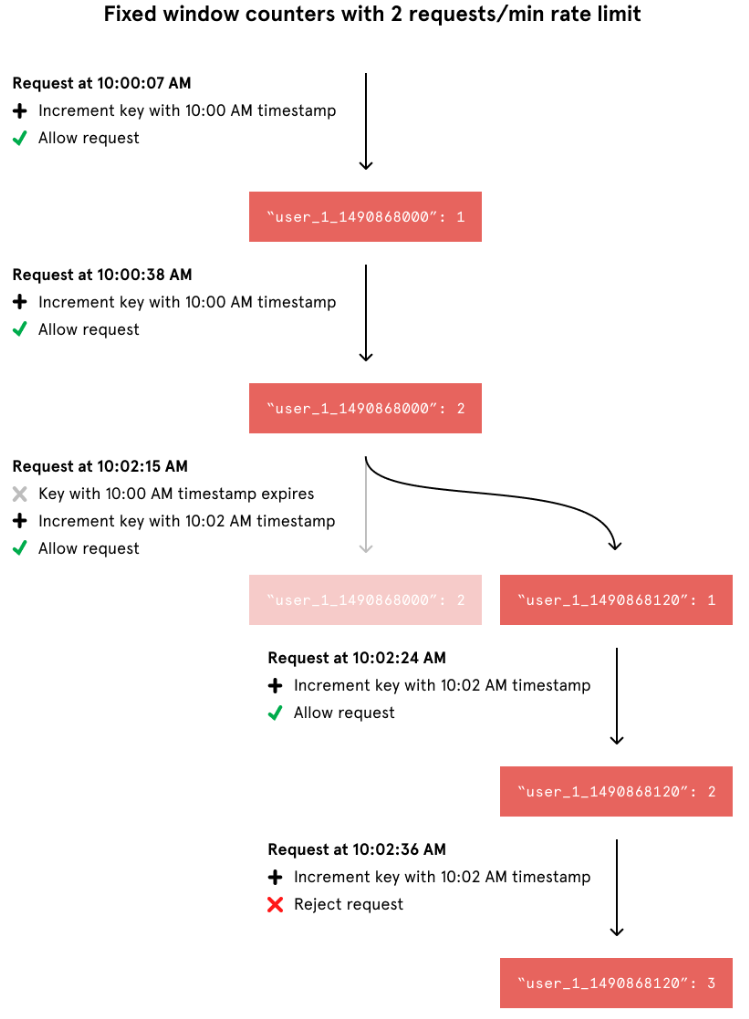
위 예제를 보면 요청 1-3은 1번 윈도우에 속하기 때문에 동일한 레디스 키에 데이터가 축적된다. 그리고 해당 윈도우는 3개의 요청을 받을 수 있으므로 모든 요청이 허용된다.
알고리즘
유저가 요청을 보내면,
- 현재 윈도우가 요청을 수용할 수 있는지 확인한다.
- 한계치를 넘었다면 요청이 버려진다.
- 한계치를 넘지 않았다면 카운터를 증가시킨다. (레디스 키에 해당하는 값을 INCR시킨다)
장점
- 이해하기 쉽고 메모리 효율적이다.
- 한도가 단위 시간 윈도우 끝에서만 초기화되는 유즈케이스에 가장 적합하다. 예를 들어 제한이 1분당 10개의 요청이라면 매 윈도우(오전 10:00:00 ~ 10:00:59까지)에서 10개의 요청을 허용하며 오전 10:01:00에 한도가 초기화된다. 오전 10:00:30 ~ 오전 10:01:29 사이에 20개의 요청이 허용되었다 하더라도 오전 10:00:00 ~ 오전 10:00:59까지가 하나의 윈도우이고 오전 10:01:00 ~ 오전 10:01:59까지는 또 다른 윈도우이기 때문에 문제가 없다. 이 알고리즘이 Fixed Window라고 불리는 이유는 Sliding Window와는 다르게 작동하기 때문이다.
단점
- 윈도우 끝 시점에 트래픽이 급증하는 경우 실시간으로 윈도우를 추적해야하는 유즈케이스에 적합하지 않다.
- 예제 1: 분당 10개의 제한일 때 유저가 0:59에 10개의 메시지를 받고 1:01에 10개의 메시지를 받을 수 있다.
- 예제 2: 분당 10개의 제한일 때 요청이 10:00:30에 시작하여 10:00:59에 끝났다면 추가 요청들은 10:01:29까지 허용되지 않는다. 10:00:30에 요청이 시작되었기 때문에 추가 요청에 대한 한도는 1분 이후인 10:01:29에 초기화된다.
Sliding Window Logs
위에서 이야기했듯이 고정 윈도우 카운터 알고즘은 윈도우 중간에서 더 많은 요청을 처리할 수 있는 약점이 있다. 그리고 이러한 문제는 슬라이딩 윈도우 알고리즘을 통해 해결할 수 있다.
- 이 알고리즘은 요청의 타임스탬프를 지속적으로 추적한다. 타임스탬프 데이터는 레디스의 Sorted Set과 같은 자료구조를 통해 저장된다.
- 새로운 요청이 오면 오래된 타임스탬프를 제거한다. (오래된 타임스탬프는 현재 시간 윈도우의 시작보다 오래된 것이다) 타임스탬프를 Sorted Set에 정렬된 순서로 저장함으로써 효율적으로 오래된 타임스탬프를 찾을 수 있다.
- 새 요청의 타임스탬프를 로그에 저장한다.
- 로그의 사이즈가 허용치와 작거나 같으면 요청은 허용된다. 반대의 경우에 요청은 버려진다.

알고리즘
요청이 올 때 마다 슬라이딩 윈도우 로그 알고리즘은 타임스탬프의 정렬값을 사용하여 Sorted Set에 데이터를 새롭게 저장한다. 이를 통해 효율적으로 오래된 타임스탬프를 제거할 수 있고 제거 후 남은 개수를 계산할 수 있다. 그러면 Sorted Set의 크기는 가장 최근 슬라이딩 윈도우 요청수와 같아진다.
유저의 요청이 오면,
- Sorted Set에서 현재 윈도우에 해당하는 로그 개수를 모두 가져와서 허용치를 넘었는지 확인한다. 현재 시간이 10:00:27이고 허용 비율이 분당 100개라면 이전 윈도우(10:00:27 - 60 = 09:59:28)부터 현재 시간(10:00:27)까지의 모든 로그를 조회한다.
- 허용치를 넘었다면 요청은 버려진다.
- 넘지 않았다면 고유한 ID를 Sorted Set에 추가한다.
이를 레디스를 활용한 구체적인 방법으로 다시 설명하자면 다음과 같다. 유저의 요청이 오면, (각 윈도우는 1분으로 제한한다)
- ZRemRangeByScore를 사용하여 Sorted Set에서 1분보다 오래된 모든 요소를 제거한다. 이를 통해 최근 1분간의 요소만 남길 수 있다.
- ZAdd를 통해 현재 요청의 타임스탬프를 저장한다.
- ZRange(0, -1)를 통해 Sorted Set에 저장된 모든 요소를 가져오고 허용치를 초과했는지 검사 후 요청을 허용하거나 버린다.
- 업데이트 시 Sorted Set의 TTL을 갱신하여 일정 시간동안 사용되지 않으면 자동으로 정리되도록 한다.
위 모든 명령들은 MULTI 명령어를 통해 원자적으로 수행할 수 있기 때문에 이 알고리즘은 여러 프로세스에 공유될 수 있다. 타임스탬프(초, 밀리초, 마이크로초)를 선택할 때는 주의해야한다. Sorted Set은 집합이기 때문에 중복을 허용하지 않는다. 따라서 동일한 타임스탬프에 여러 요청이 들어오면 하나로 간주된다.
장점
- 슬라이딩 윈도우 로그 알고리즘은 완벽하게 작동한다. 이 알고리즘을 통해 Rate Limiter를 구현하면 매우 높은 정확도를 가질 수 있다. 롤링 윈도우에서 요청은 허용치를 초과할 수 없다.
단점
- 슬라이딩 윈도우 로그 알고리즘은 요청이 버려져도 타임스탬프를 Sorted Set에 저장하기 때문에 많은 메모리를 사용한다.
Sliding Window Counter
슬라이딩 윈도우 카운터 알고리즘은 Fixed Window Counter 알고리즘과 Sliding Window Logs 알고리즘을 결합한 알고리즘이다. 보통 다음과 같은 2가지 방법으로 구현된다.
방법 1
시간당 100개의 요청을 허용하는 Rate Limiter를 구현한다고 가정하다. 이 때 버켓 사이즈가 20분이라면 3개의 버켓으로 나눠질 것이다.
{
"2AM-2:20AM": 10,
"2:20AM-2:40AM": 20,
"2:40AM-3:00AM": 30
}만약 요청이 2:50AM에 온다면 현재 버켓을 포함한 마지막 3개의 버켓에서 총 요청 수를 계산한다. 위의 경우 요청 수가 60으로 합산된다. (보통 100보다 작음) 따라서 새로운 요청이 2:40AM ~ 3:00AM 버켓에 추가된다.
{
"2AM-2:20AM": 10,
"2:20AM-2:40AM": 20,
"2:40AM-3:00AM": 31
}
방법 2
슬라이딩 윈도우 카운터 알고리즘에서 고정된 윈도우 크기 대신 롤링 윈도우를 사용하면 트래픽 급증에 대응할 수 있다. 윈도우는 일반적으로 현재 타임스탬프의 최하단으로 정의되므로 60초 윈도우에서 12:03:15는 12:03:00 윈도우에 포함된다.
예를 들어 API에 대해 시간당 100개의 요청으로 제한하고 싶다고 가정해보자. 윈도우 12:00 ~ 1:00 동안 84개의 요청이 있었고 현재 윈도우인 1:00 ~ 2:00에는 15분전에 시작된 36개의 요청이 있다.
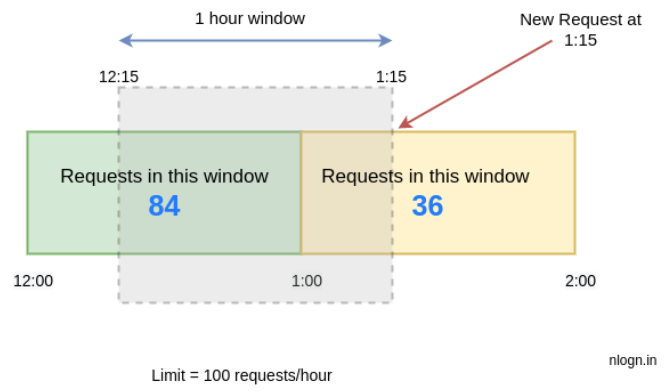
이제 1:15에 새로운 요청이 온다면 이 요청을 수락할 지 거부해야할 지 결정해야하는데 이 때 근사치를 기반으로 계산한다.
limit = 100 requests/hour
rate = ( 84 * ((time interval between 1:00 and 12:15) / rolling window size) ) + 36
= 84 * ((60 - 15)/60) + 36
= 84 * 0.75 + 36
= 99
rate < 100
hence, we will accept this request.현재 윈도우인 12:15 ~ 1:15에는 99개의 요청이 있으므로 이는 한계치인 시간당 100개의 요청보다 작은 값이다. 따라서 이 요청은 허용된다. 그러나 그 이후의 요청은 버려진다.
이를 좀 더 쉽게 설명해보자. Rate limiter가 시간 당 100개의 요청을 허용한다고 가정하자. 이전 시간에 84개의 요청이 있었고 현재 시간에 36개의 요청이 있다. 새로운 요청이 현재 시간의 25% 지점에서 도착한 경우 롤링 윈도우내의 요청 수는 다음 공식을 통해 계산된다.
현재 윈도우 요청 수 + (이전 윈도우 요청 수 * 롤링 윈도우와 이전 시간 창의 겹치는 비율)
위 공식을 사용하면 36 + (84 * 75%) = 99가 된다. Rate limiter가 시간당 100개의 요청을 허용하므로 현재 요청은 허용된다.
장점
- 메모리 효율적이다.
- 이전 시간 윈도우의 평균 비율을 기반으로 하기 때문에 스파이크 트래픽에 적절히 대응할 수 있다.
단점
- 엄격하지 않은 윈도우에만 적용된다. 실제 요청 비율에 대한 근사치일 뿐이며 이는 이전 시간 윈도우의 요청이 균등하게 분포되어 있다고 가정하기 때문이다. 그러나 이 문제는 생각보다 심각하지 않을 수 있다. Cloudflare의 실험에 따르면 4억건의 요청 중 단 0.003%만이 잘못 허용/제한되었기 때문이다.
만약 레디스를 사용한다면 해시 자료구조를 사용하여 공간 효율성을 극대화할 수 있다.
어디에 Rate Limiter를 둬야 할까
Rate Limiter는 클라이언트 사이드 또는 서버 사이드 어디에도 위치할 수 있다.
- 클라이언트 사이드: 일반적으로 조작의 가능성이 있기 때문에 대다수의 상황에서 좋지 않은 선택이다.
- 서버 사이드: 서버 사이드에 위치한 경우 아래와 같다.

이것보다 좋은 선택지가 있다. API서버에 Rate limiter를 위치하는 대신 요청이 API서버에 도달하기 전에 처리할 수 있도록 미들웨어에 위치시키는 것이다.
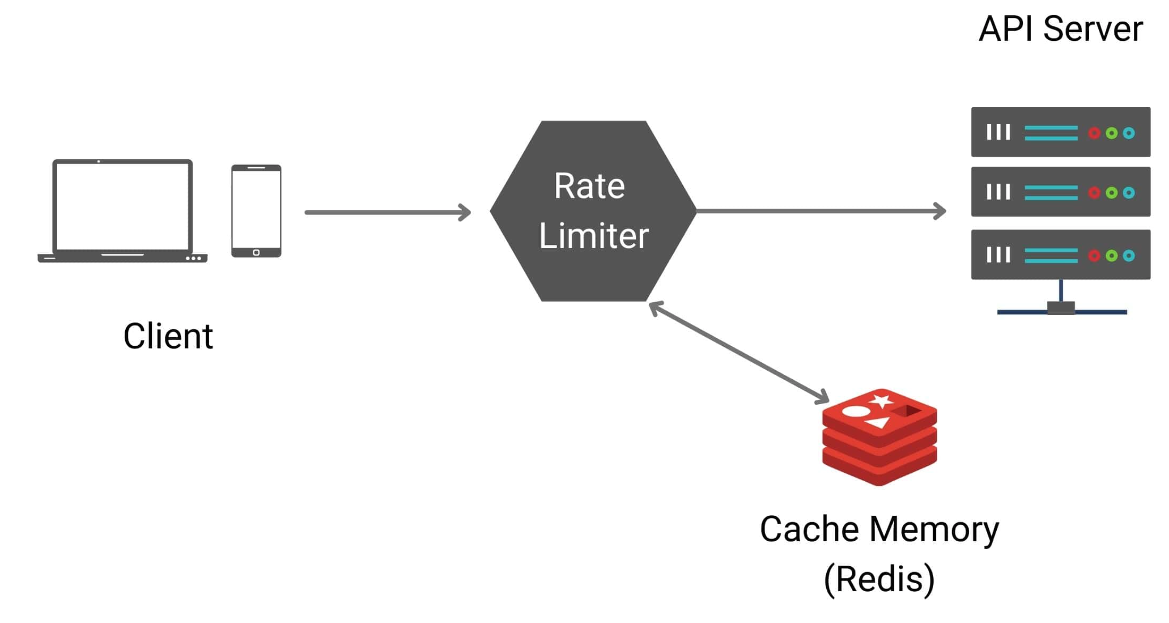
일반적으로 Rate limiter를 미들웨어에 위치시키는 것은 아키텍처 관점에서 좋은 선택지가 된다.
- API와 같은 다른 마이크로 서비스와 분리된다. 이는 다른 모든 구성 요소와 독립적으로 미들웨어를 확장할 수 있게 한다.
- 여러 마이크로서비스가 여러 개의 API를 노출하고 있을 때 각 마이크로서비스마다 Rate limiter를 구현할 필요가 없다. 하나의 Rate limiter를 미들웨어에 위치시킴으로써 모든 API에 적용할 수 있다. 이를 통해 중복 코드도 방지한다.
Distributed Rate Limiter
하나의 Rate limiter로 수백만명의 사용자의 트래픽을 제어하긴 충분치 않을 수 있다. 하지만 여러개의 Rate limiter를 사용하는 경우 데이터 동기화가 필요한데 이는 오버헤드가 된다. 하나의 Rate limiter는 다른 Rate limiter의 남은 할당량을 어떻게 알 수 있을까? 이를 처리하는 두 가지 방법이 있다.
- Sticky Session을 사용하여 동일 클라이언트가 동일한 Rate limiter로 요청을 보내도록 한다. 하지만 이 방법은 확장성도 없고 유연하지 않기 때문에 권장되지 않는다.
- 레디스와 같은 중앙 집중식 저장소를 사용한다.
Reference
https://systemsdesign.cloud/SystemDesign/RateLimiter